 shardingsphere
shardingsphere
Empowering Data Intelligence with Distributed SQL for Sharding, Scalability, and Security Across All Databases.
Top Related Projects

Free and Open Source, Distributed, RESTful Search Engine

Vitess is a database clustering system for horizontal scaling of MySQL.

CockroachDB — the cloud native, distributed SQL database designed for high availability, effortless scale, and control over data placement.

YugabyteDB - the cloud native distributed SQL database for mission-critical applications.

TiDB is built for agentic workloads that grow unpredictably, with ACID guarantees and native support for transactions, analytics, and vector search. No data silos. No noisy neighbors. No infrastructure ceiling.
Quick Overview
Apache ShardingSphere is an open-source ecosystem for distributed database solutions. It provides a sharding-scaling, distributed transaction, and database governance platform, aiming to transform any database into a distributed database system while enhancing it with sharding, elastic scaling, encryption features, and more.
Pros
- Flexible and powerful sharding strategies for horizontal scaling
- Supports multiple databases (MySQL, PostgreSQL, Oracle, SQLServer)
- Provides distributed transaction capabilities
- Offers database governance features like dynamic configuration, monitoring, and security
Cons
- Steep learning curve for complex configurations
- Performance overhead for certain operations due to additional abstraction layer
- Limited support for NoSQL databases
- May require significant changes to existing applications for full utilization
Code Examples
- Basic sharding configuration:
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());
shardingRuleConfig.getTableRuleConfigs().add(getOrderItemTableRuleConfiguration());
shardingRuleConfig.getBindingTableGroups().add("t_order, t_order_item");
- Distributed transaction usage:
TransactionTypeHolder.set(TransactionType.XA);
try (Connection conn = dataSource.getConnection()) {
conn.setAutoCommit(false);
// Execute SQL statements
conn.commit();
} catch (SQLException ex) {
conn.rollback();
}
- Encryption configuration:
EncryptRuleConfiguration encryptRuleConfig = new EncryptRuleConfiguration();
encryptRuleConfig.getEncryptors().put("aes_encryptor", new EncryptorRuleConfiguration("AES", new Properties()));
EncryptColumnRuleConfiguration columnConfig = new EncryptColumnRuleConfiguration("", "user_encrypt", "", "aes_encryptor");
encryptRuleConfig.getTables().put("t_user", new EncryptTableRuleConfiguration(Collections.singletonMap("user_id", columnConfig)));
Getting Started
- Add ShardingSphere dependency to your project:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.1.1</version>
</dependency>
- Configure sharding rule in your application:
DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(
createDataSourceMap(), Collections.singleton(createShardingRuleConfiguration()), new Properties());
- Use the configured DataSource in your application:
String sql = "SELECT * FROM t_order WHERE user_id = ?";
try (
Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setInt(1, 10);
try (ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
// Process result set
}
}
}
Competitor Comparisons
Free and Open Source, Distributed, RESTful Search Engine
Pros of Elasticsearch
- Powerful full-text search capabilities with advanced querying and analytics
- Distributed architecture for high scalability and fault tolerance
- Rich ecosystem with extensive plugins and integrations
Cons of Elasticsearch
- Higher resource consumption, especially for large-scale deployments
- Steeper learning curve for complex configurations and optimizations
- Limited support for ACID transactions compared to traditional databases
Code Comparison
Elasticsearch query example:
GET /my_index/_search
{
"query": {
"match": {
"title": "elasticsearch"
}
}
}
ShardingSphere SQL example:
SELECT * FROM t_order WHERE order_id = 1
Key Differences
- Elasticsearch is primarily a search and analytics engine, while ShardingSphere focuses on database sharding and scaling
- ShardingSphere provides a SQL-based interface, whereas Elasticsearch uses a REST API with JSON-based queries
- Elasticsearch excels in full-text search and log analysis, while ShardingSphere is better suited for distributed relational database management
Both projects serve different primary purposes but can be complementary in certain scenarios. Elasticsearch is ideal for search-heavy applications, while ShardingSphere is better for scaling traditional relational databases across multiple nodes.
Vitess is a database clustering system for horizontal scaling of MySQL.
Pros of Vitess
- More mature project with longer history and wider adoption in production environments
- Better support for large-scale horizontal sharding and multi-datacenter replication
- Native integration with Kubernetes for easier deployment and scaling
Cons of Vitess
- Steeper learning curve and more complex setup compared to ShardingSphere
- Limited support for databases other than MySQL
- Less flexibility in terms of customization and extensibility
Code Comparison
Vitess (VTGate query routing):
func (vtg *VTGate) ExecuteKeyspaceIds(ctx context.Context, sql string, bindVariables map[string]*querypb.BindVariable, keyspace string, keyspaceIds [][]byte, tabletType topodatapb.TabletType, session *vtgatepb.Session, notInTransaction bool, options *querypb.ExecuteOptions) (*sqltypes.Result, error) {
// Implementation details
}
ShardingSphere (ShardingRule):
public final class ShardingRule implements BaseRule {
private final ShardingRuleConfiguration ruleConfiguration;
private final ShardingDataSourceNames shardingDataSourceNames;
// More fields and methods
}
Both projects aim to solve database scaling challenges, but Vitess focuses more on horizontal sharding for MySQL, while ShardingSphere provides a more general-purpose sharding solution with support for multiple databases. Vitess excels in large-scale deployments, while ShardingSphere offers more flexibility and easier integration for smaller to medium-sized applications.
CockroachDB — the cloud native, distributed SQL database designed for high availability, effortless scale, and control over data placement.
Pros of CockroachDB
- Fully distributed SQL database with strong consistency and high availability
- Built-in support for geo-partitioning and multi-region deployments
- Automatic sharding and rebalancing without manual intervention
Cons of CockroachDB
- Higher resource requirements and potentially higher operational costs
- Steeper learning curve for administrators unfamiliar with distributed systems
- Limited support for certain SQL features and stored procedures
Code Comparison
CockroachDB (Go):
func (n *Node) startGossip(ctx context.Context, stopper *stop.Stopper) {
n.gossip.Start(n.grpcServer.Addr())
n.gossip.EnableSimulationCycles()
n.storePool.Start(stopper, n.gossip)
}
ShardingSphere (Java):
public final class ShardingDataSource extends AbstractDataSourceAdapter {
public ShardingDataSource(final Map<String, DataSource> dataSourceMap,
final ShardingRule shardingRule,
final Properties props) throws SQLException {
super(dataSourceMap);
this.shardingContext = new ShardingContext(dataSourceMap, shardingRule, props);
}
}
ShardingSphere focuses on database sharding and distributed transaction management, while CockroachDB is a complete distributed SQL database solution. ShardingSphere offers more flexibility in integrating with existing databases, whereas CockroachDB provides a more comprehensive out-of-the-box distributed database experience.
YugabyteDB - the cloud native distributed SQL database for mission-critical applications.
Pros of YugabyteDB
- Fully distributed SQL database with high availability and horizontal scalability
- Native multi-region and multi-cloud support
- ACID-compliant transactions with strong consistency
Cons of YugabyteDB
- Steeper learning curve for deployment and management
- Limited ecosystem compared to more established databases
- Higher resource requirements for small-scale deployments
Code Comparison
YugabyteDB (C++):
Status YBClient::CreateTable(const string& table_name,
const Schema& schema,
const CreateTableOptions& opts) {
return impl_->CreateTable(table_name, schema, opts);
}
ShardingSphere (Java):
public final class ShardingRule implements BaseRule {
private final ShardingRuleConfiguration ruleConfiguration;
private final ShardingDataSourceNames shardingDataSourceNames;
private final Collection<TableRule> tableRules;
}
YugabyteDB focuses on distributed SQL implementation, while ShardingSphere provides a sharding layer for existing databases. YugabyteDB's code deals with table creation in a distributed environment, whereas ShardingSphere's code defines sharding rules and configurations. Both projects aim to improve database scalability and performance, but with different approaches and architectures.
TiDB is built for agentic workloads that grow unpredictably, with ACID guarantees and native support for transactions, analytics, and vector search. No data silos. No noisy neighbors. No infrastructure ceiling.
Pros of TiDB
- Designed as a distributed NewSQL database, offering strong consistency and horizontal scalability
- Built-in support for HTAP (Hybrid Transactional/Analytical Processing) workloads
- Native compatibility with MySQL protocol, making migration easier
Cons of TiDB
- Higher resource requirements and complexity for deployment
- Steeper learning curve due to its distributed nature and unique architecture
- Limited support for certain advanced MySQL features
Code Comparison
TiDB (SQL parser example):
func (p *Parser) parseSelectStmt(ctx context.Context) (ast.StmtNode, error) {
lexer := p.lexer
if err := lexer.NextTokenAfterWhitespace(); err != nil {
return nil, errors.Trace(err)
}
// ... (additional parsing logic)
}
ShardingSphere (SQL parser example):
public final class SQLParserEngine {
public SQLStatement parse(final String sql, final boolean useCache) {
ParsingHook parsingHook = new ParsingHook();
parsingHook.start(sql);
try {
// ... (parsing logic)
} finally {
parsingHook.finishSuccess();
}
}
}
Both projects implement SQL parsing, but TiDB uses Go while ShardingSphere uses Java. TiDB's parser is more tightly integrated with its distributed architecture, while ShardingSphere's parser is designed for flexibility across different database systems.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Apache ShardingSphere - Enterprise Distributed Database Ecosystem
Building the standards and ecosystem on top of heterogeneous databases, empowering enterprise data architecture transformation
Official Website: https://shardingsphere.apache.org/

![]()
![]()



|

|

|
|---|
OVERVIEW
Apache ShardingSphere is positioned as Database Plus, a standard and ecosystem built on top of heterogeneous databases. As an operating system layer above databases, ShardingSphere does not create new databases but focuses on maximizing the computing capabilities of existing databases, providing unified data access and enhanced computing capabilities.
Database Plus Core Concept: By building a standardized and scalable enhancement layer above databases, it makes heterogeneous databases as simple to use as a single database, providing unified governance capabilities and distributed computing capabilities for enterprise data architectures.
Connect, Enhance, and Pluggable are the three core pillars of Apache ShardingSphere:
-
Connect: Building database upper-layer standards, quickly connecting applications with multi-modal heterogeneous databases through flexible adaptation of database protocols, SQL dialects, and storage formats, providing unified data access experience;
-
Enhance: As a database computing enhancement engine, transparently providing enterprise-grade capabilities including distributed computing (data sharding, readwrite-splitting, SQL federation), data security (encryption, masking, audit), traffic control (circuit breaker, rate limiting), and observability (monitoring, tracing, analysis);
-
Pluggable: Adopting a micro-kernel + 3-layer pluggable architecture to achieve complete decoupling of kernel, functional components, and ecosystem integration. Developers can flexibly customize unique data architecture solutions that meet enterprise needs, just like building with LEGO blocks.
Differentiation Advantages:
- vs Distributed Databases: More lightweight, protecting existing investments, avoiding vendor lock-in
- vs Traditional Middleware: Richer features, more complete ecosystem, more flexible architecture
- vs Cloud Vendor Solutions: Support multi-cloud deployment, avoid technology binding, autonomous and controllable
ShardingSphere became an Apache Top-Level Project on April 16, 2020, and has been adopted by 19,000+ projects worldwide.
DUAL-ACCESS ARCHITECTURE DESIGN
ShardingSphere adopts a unique dual-access architecture design, providing two access ends - JDBC and Proxy - that can be deployed independently or in hybrid deployment, meeting diverse requirements for different scenarios.
ShardingSphere-JDBC: Lightweight Access End
Positioning: Lightweight Java framework, enhanced JDBC driver
Core Features:
- Client-side direct connection: Shares resources with applications, decentralized architecture
- High performance, low overhead: Direct database connection with minimal performance loss
- Complete compatibility: Compatible with all ORM frameworks (MyBatis, JPA, Hibernate, etc.)
- Zero additional deployment: Provided as JAR package, no independent deployment and dependencies required
Use Cases: High-performance Java applications, integrated deployment with business applications, pursuing ultimate performance
ShardingSphere-Proxy: Enterprise Access End
Positioning: Transparent database proxy, independently deployed server-side
Core Features:
- Static entry point: Independent deployment from applications, providing stable database access entry
- Heterogeneous language support: Supports any MySQL/PostgreSQL protocol compatible client
- DBA friendly: Database operation and maintenance management interface, convenient for O&M personnel
- Enterprise-grade features: Supports cluster deployment, load balancing, failover
Use Cases: Heterogeneous language environments, database operation and maintenance management, enterprise applications requiring unified access entry
Hybrid Architecture Advantages
By hybridizing ShardingSphere-JDBC and ShardingSphere-Proxy with unified configuration through the same registry center, you can flexibly build application systems suitable for various scenarios:
- Architectural flexibility: Architects can freely adjust the optimal system architecture
- Scenario adaptability: Select the most suitable access method according to different business scenarios
- Unified management: Single configuration, multi-end collaboration, simplifying O&M complexity
- Progressive evolution: Support smooth evolution path from JDBC to Proxy
AI ABSTRACTION
![]()
![]()
DOCUMENTATIONð
![]()
![]()
For full documentation & more details, visit: Docs
CONTRIBUTIONðð§ð»
For guides on how to get started and setup your environment, contributor & committer guides, visit: Contribution Guidelines
Team
We deeply appreciate community contributors for their dedication to Apache ShardingSphere.
COMMUNITY & SUPPORTðð¤
:link: Mailing List. Best for: Apache community updates, releases, changes.
:link: GitHub Issues. Best for: design discussions, bug reports, or anything development related.
:link: Slack channel. Best for: instant communications and online meetings, sharing your applications.
:link: X. Best for: keeping up to date on everything ShardingSphere.
:link: LinkedIn. Best for: professional networking and career development with other ShardingSphere contributors.
PROJECT STATUS
:white_check_mark: Version 5.5.4-SNAPSHOT: Actively under development :tada:
ð For the release notes, follow this link to the relevant GitHub page.
:soon: Version 5.5.4
We are currently developing version 5.5.4, which includes multiple security enhancements and performance optimizations. Keep an eye on the milestones page of this repo for the latest development progress.
TECHNICAL ARCHITECTURE EVOLUTION
Apache ShardingSphere adopts a micro-kernel + 3-layer pluggable architecture, achieving complete decoupling of the kernel, functional components, and ecosystem integration, providing developers with ultimate flexibility and extensibility.
Micro-Kernel + 3-Layer Pluggable Model
Core Layer:
- Query optimizer: Intelligent SQL routing and execution plan optimization
- Distributed transaction: ACID transaction guarantees and consistency coordination
- Execution engine: Efficient distributed execution and result aggregation
Feature Layer:
- Data sharding, readwrite-splitting, federation query
- Data encryption, data masking, SQL audit
- Shadow database, observability, traffic control
Ecosystem Layer:
- Database protocol adaptation (MySQL, PostgreSQL, Oracle, etc.)
- Registry center integration (ZooKeeper, ETCD, etc.)
- Configuration management, service discovery, monitoring integration
Technical Innovation Highlights
Complete Decoupling Architecture:
- Database types completely decoupled, supporting rapid integration of new databases
- Functional modules completely decoupled, supporting on-demand feature combination
Apache ShardingSphere consists of two access ends - JDBC and Proxy - that can be deployed independently or in hybrid deployment, providing unified distributed database solutions for diverse application scenarios including Java isomorphism, heterogeneous languages, and cloud-native environments.
ShardingSphere-JDBC

A lightweight Java framework providing extra services at the Java JDBC layer. With the client end connecting directly to the database, it provides services in the form of a jar and requires no extra deployment and dependence.
:link: For more details, follow this link to the official website.
Note: When using ShardingSphere-JDBC adapter, pay attention to your application's memory configuration. Antlr uses an internal cache to improve performance during SQL parsing. If your application has too many SQL templates, the cache will continue to grow, occupying a large amount of heap memory. According to feedback from the ANTLR official issue#4232, this issue has not yet been optimized. When connecting your application to ShardingSphere-JDBC, it is recommended to set a reasonable heap memory size using the
-Xmxparameter to avoid OOM errors caused by insufficient memory.
ShardingSphere-Proxy

![]()

A transparent database proxy, providing a database server that encapsulates the database binary protocol to support heterogeneous languages. Friendlier to DBAs, the MariaDB, MySQL and PostgreSQL version now provided can use any kind of terminal.
:link: For more details, follow this link to the official website.
Hybrid Architecture
ShardingSphere-JDBC adopts a decentralized architecture, applicable to high-performance light-weight OLTP applications developed with Java. ShardingSphere-Proxy provides static entry and all languages support, suitable for an OLAP application and sharding databases management and operation.
Through the combination of ShardingSphere-JDBC & ShardingSphere-Proxy together with a unified sharding strategy by the same registry center, the ShardingSphere ecosystem can build an application system suitable to all kinds of scenarios.
:link: More details can be found following this link to the official website.
CORE FEATURE MATRIX
Distributed Database Core Capabilities
- Data Sharding: Horizontal sharding, vertical sharding, custom sharding strategies, automatic sharding routing
- Read/Write Splitting: Master-slave replication, load balancing, failover, read weight configuration
- Distributed Transaction: XA transactions, BASE transactions, transaction propagation
Data Security & Governance
- Data Encryption: Field-level encryption, transparent encryption, key management, encryption algorithm support
- Data Masking: Sensitive data protection, masking strategy customization, dynamic masking rules
- Access Control: Fine-grained permissions, access control, SQL firewall, security policies
Database Gateway Capabilities
- Heterogeneous Databases: MySQL, PostgreSQL, Oracle, SQL Server, Firebird, etc.
- SQL Dialect Translation: Cross-database SQL compatibility, dialect adaptation, syntax conversion
- Protocol Adaptation: Database protocol conversion, multi-protocol support, communication optimization
Full-link Stress Testing & Observability
- Shadow Database: Stress testing data isolation, environment separation, real data simulation
- Observability: Performance monitoring, distributed tracing, QoS analysis, metrics collection
- Traffic Analysis: SQL performance analysis, traffic statistics, bottleneck identification
Enterprise-grade Features
- High Availability: Cluster deployment, fault recovery, service discovery, health checks
- Cloud Native: Containerized deployment, Kubernetes integration, native image support
- Monitoring & Alerting: Real-time monitoring, alert notifications, performance metrics, O&M dashboard
Roadmap
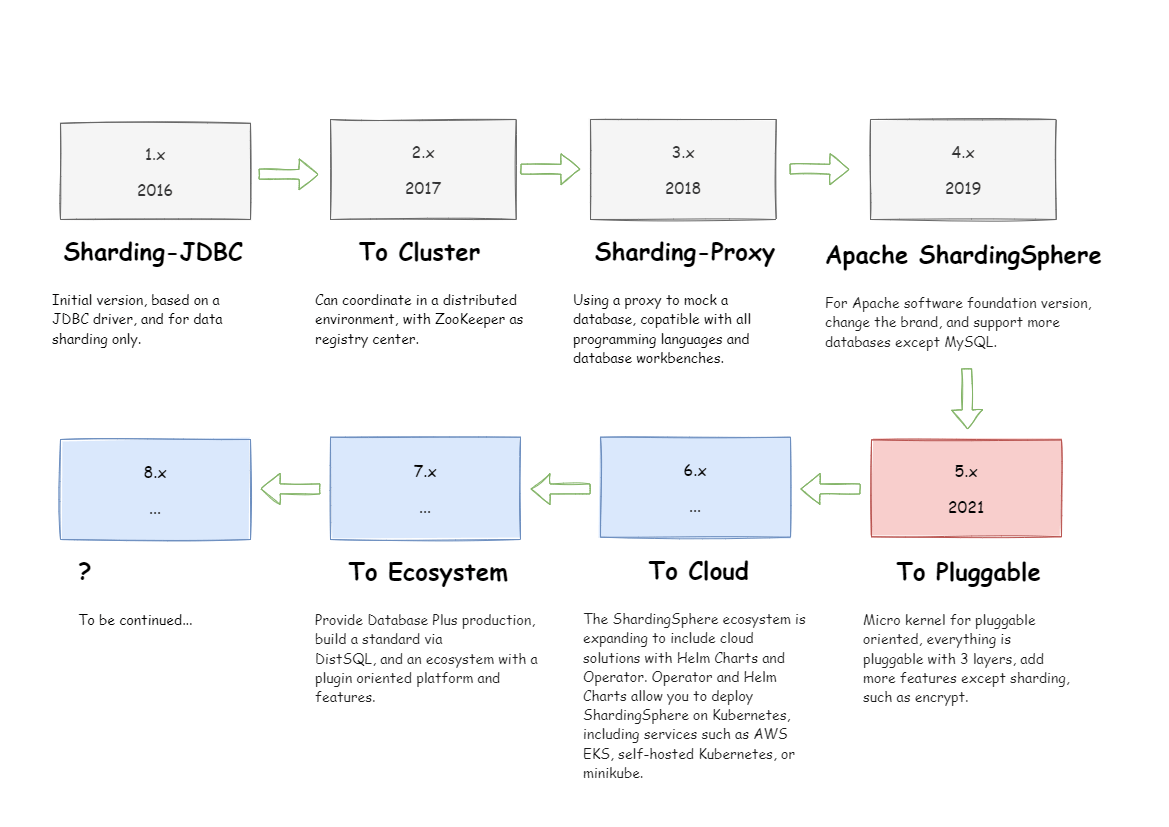
How to Build Apache ShardingSphere
Check out Wiki section for details on how to build Apache ShardingSphere and a full guide on how to get started and setup your local dev environment.
Landscapes

![]()
Apache ShardingSphere enriches the CNCF CLOUD NATIVE Landscape.
Top Related Projects
Free and Open Source, Distributed, RESTful Search Engine
Vitess is a database clustering system for horizontal scaling of MySQL.
CockroachDB — the cloud native, distributed SQL database designed for high availability, effortless scale, and control over data placement.
YugabyteDB - the cloud native distributed SQL database for mission-critical applications.
TiDB is built for agentic workloads that grow unpredictably, with ACID guarantees and native support for transactions, analytics, and vector search. No data silos. No noisy neighbors. No infrastructure ceiling.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot